Shakespeare's Early Editions: Computational Methods for Textual Studies
What is this?
The CTS Director, Prof Gabriel Egan, is Principal Investigator on a £312,012 AHRC-funded research project running from October 2016 to March 2018 that has the following objectives:
1) To determine what the new computational techniques developed to distinguish authorship can tell us about the textual corruption and revision separating the various early editions--quartos (Q) and the 1623 Folio (F)--of the works of William Shakespeare, upon which all subsequent editions depend.
2) Where co-authorship, revision and textual corruption all contribute to Q/F differences for a single Shakespeare play, to discover how far the new methods can distinguish them.
3) To determine how best we can now explain Q/F differences for Shakespeare plays and so help today's editors to present them to modern readers, in the light of plausible theories of textual provenance, including hypotheses about how and why manuscripts of plays were recopied and how publishers received them.
This is the homepage for that project, where there will appear news about the project (see the blog below) and where all materials generated by the project will be published for anyone to use under a Creative Commons Attribution (CC BY) licence. If you want the hardcore technical details, use the link called 'Technical Repository' on the left.
See also our 'Glossary' linked there for words or concepts that are unfamiliar.
See also linked on the left our 'Play word counts' sub-project in which Dr Paul Brown provides a Python script for mass-counting of the words in plays downloaded from ProQuest's Literature Online database, and gives the results for all plays from 1564 to 1616.
So, what will the project do exactly?
We know what William Shakespeare wrote only because in his lifetime, and shortly after it, his works appeared in printed form from various small London publishers. With one small exception, we have none of his manuscripts, so all modern editions of Shakespeare are based on these surviving printed editions. About half of his works appeared during his lifetime in cheap single-play editions known as quartos and in 1623 (seven years after Shakespeare's death) a large collected works edition of 36 of his plays, known as the First Folio, was published with assistance from his fellow actors. Where we have both quarto and Folio versions of a play, they are never identical. Hundreds or thousands of 'variants' ranging from single words to whole lines, speeches, and even scenes are present or absent in one or other edition, or are entirely reworded and/or placed in a different part of the play. Unlike the plays, Shakespeare's poems were well published and present far fewer editorial problems.
Despite centuries of study, we cannot satisfactorily explain the quarto/Folio (Q/F) variants. Some will be errors made in the printing of one or other early edition, or in the prior copying of the lost manuscripts from which those printings were made. Others will be the results of censorship that required the toning down of religious expressions used as swear-words. Others still will be the results of Shakespeare changing his mind and revising a play after first composing it, or his fellow actors changing it with or without his consent. Just which reason explains each variant is hard to say because their results can be similar. As readers and editors of Shakespeare we want to find out which reason explains each variant because we want to correct the printer's errors and censorship but not to undo second thoughts and other kinds of revision in order to show modern readers what Shakespeare actually wrote. Where he or his fellows revised a play, we want to see how it stood before and after the revision in order to understand the motivations for changing it.
The newest discoveries about Shakespeare's habits of writing concern co-authorship. Scholars used to believe that except for short periods at the start and end of his career, Shakespeare habitually wrote on his own, but we now know that as many as one-third of his works were co-written with other dramatists. This has been shown by multiple independent studies using computational stylistics, which measure features of a writer's style that are invisible to the naked eye but can be counted by machines. For the past three decades, prevailing theories of authorship have suggested that where two writers collaborate on a work they blend their styles--effectively imitating one another--so that it would be all but impossible to decide later who wrote each part of the resulting composite work. Computer-aided analysis has proved this to be untrue: personal traits of writing can be discerned even where writers attempt to efface them.
This project will use the latest techniques in computational stylistics to study the problem of the Q/F variants. The techniques are particularly suited to (indeed, were first developed for) the discrimination of random corruption from systematic alteration. This discrimination goes to the heart of the Q/F variants problem: we want to know which differences result from mere errors in transmission and which are something else. Now that we have reliable tools to discriminate authorial styles, and have a reasonable set of baseline style-profiles for most of Shakespeare's fellow dramatists, we ought to be able to see how far artistic revision by Shakespeare and/or his collaborators caused the differences between the early editions, which remain our only access to Shakespeare. The better we understand the Q/F differences, the better account we can give of what Shakespeare actually wrote.
Project blog
February 2018
The Postdoctoral Research Associate on the project, Dr Mike Stout, finished this month. He has left a mountain of research results that the Principal Investigator, Gabriel Egan, will work through to produce research papers. Currently arising from this work are paper scheduled to be given at the following conferences: 'Bridging Gaps, Creating Links: The Qualitative-Quantitative Interface in the Study of Literature' at the University of Padua on 7-9 June 2018, 'Shakespeare Studies Today: The ninth biennial meeting of the British Shakespeare Association at Queen's University Belfast on 14-17 June 2018, and the 'International Shakespeare Conference' at the Shakespeare Institute, Stratford-upon-Avon, on 22-27 July 2018.
December 2017
To date the project has created the following transcriptions of early editions of Shakespeare in TEI P4 XML markup for use in experiments.
1 Henry 4_Q1
1 Henry 4_F
2 Henry 4_Q1
2 Henry 6_Q1
3 Henry 6_F
Hamlet_F
Hamlet_Q2
Henry_5_Q1
Henry_5_F
King Lear_F
King Lear_Q1
King Lear_Q2
Merchant of Venice_Q1
Merchant of Venice_F
Merry Wives_Q1
Midsummer Night's Dream_F
Much Ado_F
Othello_F
Othello_Q1
Pericles_Q1
Richard 2_F
Richard 3_F
Romeo and Juliet_Q1
Romeo and Juliet_Q2
Romeo and Juliet_F
Taming of the Shrew_Taming of a Shrew (1594)
Taming of the Shrew_F
Titus Andronicus_Q1
Troilus and Cressida_Q1
Troilus and Cressida_F
Spanish Tragedy 1592
The full set of transcriptions will be posted here shortly; in the mean time any investigator wanting these transcriptions is welcome to them -- just ask.
October 2017
DMU undergraduates Payge Temple and Keenan Jones joined the project as further XML coders in order to tackle the large amount of plays in both Folio and Quarto editions that still required formatting.
 Payge Temple
Payge Temple
 Keenan Jones
Keenan Jones
The rate of creating XML transcriptions for the project has accelerated with Payge and Keenan working under Kyonnah's supervision.
August 2017
The project is currently focussing on trying to replicate Arthur Kinney's results in his chapter on King Lear in Shakespeare, Computers, and the Mystery of Authorship. Using our encoded texts we can get results very close to those shown in Kinney's Figures 9.1, 9.2, and 9.3:
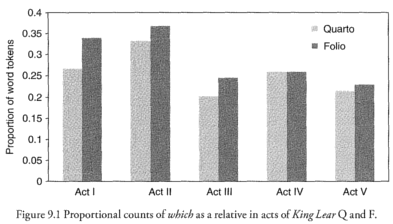
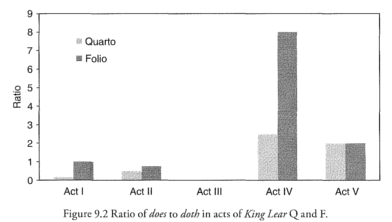
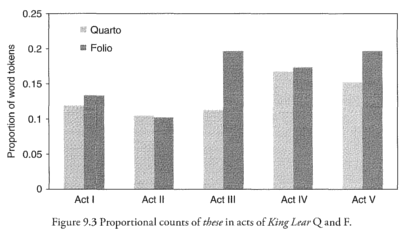
June 2017
The XML coding of each text creates three categories for consideration: the original full file, a common file (drawing attention to the elements that are present in both quarto and folio editions), and an editions only file (drawing attention to the elements that are present in either the folio or quarto, but not the other). The regularisation of texts in the XML coding stage is obviously a major hazard in a project like this, as the irregularities in an edition of a text is exactly the focus. However, some small alterations to the texts in this stage are required. Examples of such alterations are: the joining together of words that have been hyphenated due to previous formatting decisions, and the swapping of æ for ae. Both of these alterations are made in the coding stage in order to make the analysis stage of the text much easier and to avoid the accidental neglect of possibly important information. In the analysis stages of this project, cross tabulation is used in order to focus in on very specific pairings and groupings of information. An example of this could be the decision to focus in on the use of the word thy only in King Lear’s speeches in Act 3. With cross tabulation, this kind of filtering is easily made possible for such a project.
May 2017
The ‘SEE TKL Exp2 R analysis’ entry in the Technical Repository displays the chosen function words to be observed within King Lear in this project, which are: that, which, who, do, does, doth, these, this, those, thine, and thy. The information in this entry also shows us each word’s frequency in each scene of the Folio and quarto editions of the play. In performing this test, the project also hopes to reproduce the results seen in Arthur F. Kinney’s chapter ‘Transforming King Lear’ in Shakespeare, Computers, and the Mystery of Authorship. In order to do this, certain steps and decisions had to be made. Once King Lear was coded into XML, the decision to analyse the play by scenes was made; as the sections and passages that Kinney used in his research were not available. The decision to isolate specific speeches was also made as a more efficient process versus the time consuming and expensive process of moving a window of 2000 words along the text for close analysis. The stage directions of a text were separated from speeches as they offer a different kind of data that may add anomalous results and may not answer the questions that this project seeks to answer. This is easily achieved with XML coding, as the tags allow XQuery to easily differentiate between speeches and stage directions.
April 2017
In the 15.3.17 entry of the ‘What’s New?’ part of the Technical Repository section of this website, some problems for consideration raised by the initial experiments are outlined. Problem 1 is a practical one and referred to as the ‘Transposition Problem’, in which a sequence of words is not different between two editions but swapped around. This situation prompts the need for a decision to be made on the way in which we effectively present the different ordering of phrases between editions. A possible solution is displayed in the same 15.3.17 entry, which suggests an edit that encodes both the deletion of material in Q1 to achieve Q2, and the insertion of material not in Q1 to achieve Q2. Problem 2 is referred to as the ‘Substitution Problem’, in which a line from King Lear is given as example to highlight the difference between when two words can be fairly easily identified as meaning the same thing, and when two words might connote dissimilar meanings. When two words are similar and can be understood to mean the same thing, there is not really a need to consider this a substitution. However, when there is a possible difference in meaning, like in ‘selfe same mettall’ and ‘self-mettle’, researchers were prompted to consider how to efficiently quantify such things. This is, however, an exciting opportunity as the creation of a kind of standard for these edition differences would greatly benefit the field of Shakespeare Studies. The third problem, referred to as the ‘Why? Problem’, takes the research of this project back to the bigger picture question of why are these editions different? The possible theories behind this question are detailed towards the end of the 15.3.17 entry, which also suggests that multiple explanations for textual differences could be present at once in some cases.
March 2017
The first two files completed by the XML coding team (the 1597 Q1 and 1599 Q2 of Romeo and Juliet) were sent off to Hugh Craig and his team at the Centre for Literary and Linguistic Computing (CLLC) based at the University of Newcastle in Australia. At this stage, Craig and his team assessed the usability and accuracy of those files. Meanwhile, in the January of 2017, In the next couple of months, we'll be initial experiments with text alignment. These experiments involved using a tool called ‘vimdiff’, which can be used to compare files and highlight the differences between them. This stage also involved trying out other ways of aligning the different editions of texts, such as: dynamic time warping, multiple sequence alignment and mapping the text into a kind of DNA or Protein alphabet layout. Comprehensive definitions and helpful examples of these terms can be found in the hyperlinks within the 10.3.17 entry, as well as the ‘Glossary’ section of this website. Whilst using each of these text alignment techniques, the ‘cost’ of making the two versions of a text line up alongside one another is also recorded and considered. In other words, if a text requires a lot of ‘warping’ or manipulation in order to get two versions to align, that equals a high level of ‘cost’.
February 2017
The project considers research from the likes of Arthur F. Kinney and Hugh Craig, particularly in their 2009 text Shakespeare, Computers, and the Mystery of Authorship, as a foundation and resource for the investigation of such questions. This project from The Centre for Textual Studies began with a search for text availability; the results from which can be found in the 'Technical Repository' section of this website. Shakespeare’s Hamlet and King Lear were then selected as useful texts in terms of Quarto and Folio availability, as well as the large amount of potential differences visible for study.
January 2017
First XML transcriptions gone to Hugh Craig's team in Australia Our project's XML Encoding Group's first two files, representing the first quarto (Q1, 1597) and second quarto (Q2, 1599) of Romeo and Juliet, have gone off to Hugh Craig and his team at the Centre for Literary and Linguistic Computing (CLLC) at the University of Newcastle in Australia. The CTS is collaborating with the CLLC on this project and we wait to hear their view on the useability and accuracy of our files. If they approve them, the files will of course (because we are an Open Access, Open Data project) be made available here for anyone else to use.
December 2016
XML Encoding Group Formed and Working We now have four XML encoders working on producing TEI XML transcriptions of the important variant early editions of Shakespeare. The most experienced of the team of Kyonnah Price, a DMU BA English graduate who learnt XML encoding during her final-year course "Textual Studies Using Computers" taught by the CTS. Joining Kyonnah are research student Dimitrios Foukis (who is learning XML as part of his PhD project) and two DMU Global Interns: Ire Ogueche and Adeniyi Olukayode. Our team:
 Kyonnah Price
Kyonnah Price
 Dimitrios Foukis
Dimitrios Foukis
 Ire Ogueche
Ire Ogueche
 Adeniyi Olukayode
Adeniyi Olukayode
November 2016
AHRC Post-Doc hired The project has interviewed and appointed Dr Michael Stout to be our Post-Doctoral Research Associate, starting on 1 February 2018. Mike comes to us with a background in applying machine learning techniques to problems in bioinformatics. He writes software in Python and Haskell (amongst others) and has used Markov Chains and Bayesian statistics in his research, all of which is very relevant for this project. His long connection with humanities projects goes back to his time at Oxford University Press when he worked on pioneering electronic publishing projects such as the Oxford English Dictionary on CD-ROM.
October 2016
And we're off The CTS's new MA student Kyonnah Price, a graduate of our BA English course on "Textual Studies Using Computers" (see the link on the left for our courses), has agreed to do the work of encoding in TEI-XML the first quarto (published in 1597) of Shakespeare's Romeo and Juliet. We have from our Prof Hugh Craig, Director of the Centre for Literary and Linguistic Computing (CLLC) at the University of Newcastle in Australia, his TEI-XML encoding of the script of John Marston's play Sophonisba (a.k.a. The Wonder of Women), marked up to show the features that his computational stylistics methods work upon. So Kyonnah will use that as her model for Q1 Romeo and Juliet and will validate her work against the teilite.dtd. (Kyonnah is using the oXygen XML Editor from SyncRo Soft Limited, which seems to be everyone's choice these days.) Once Kyonnah is done, we'll send the file back to Hugh in Australia for confirmation that it conforms to the specifications his methods rely upon.
September 2016
Despite our best efforts, the project hasn't yet been able to appoint the Post-Doctoral Research Fellow that it needs to do the necessary programming for its experiments. So, we will readvertize this post--for four weeks this time--to get the widest international field of candidates. The Post-Doc will now probably start in December 2016 or January 2017 instead of October 2016 as originally planned. The funder, the AHRC is fine with this, so long as we get done everything we planned to do by March 2018. Still, we'd better get started so let's see if we can hire any of the incoming Masters students to do a spot of TEI-XML encoding of the early editions of Shakespeare to get us going.