Information Metrics
- Added Entropy metric to Lr Analysis Latest -- measure on single speeches.
Pairwise Information Metrics
- e.d., jsd, nmi, dtw ...
*Relationship of these metrics to each other....
Notes
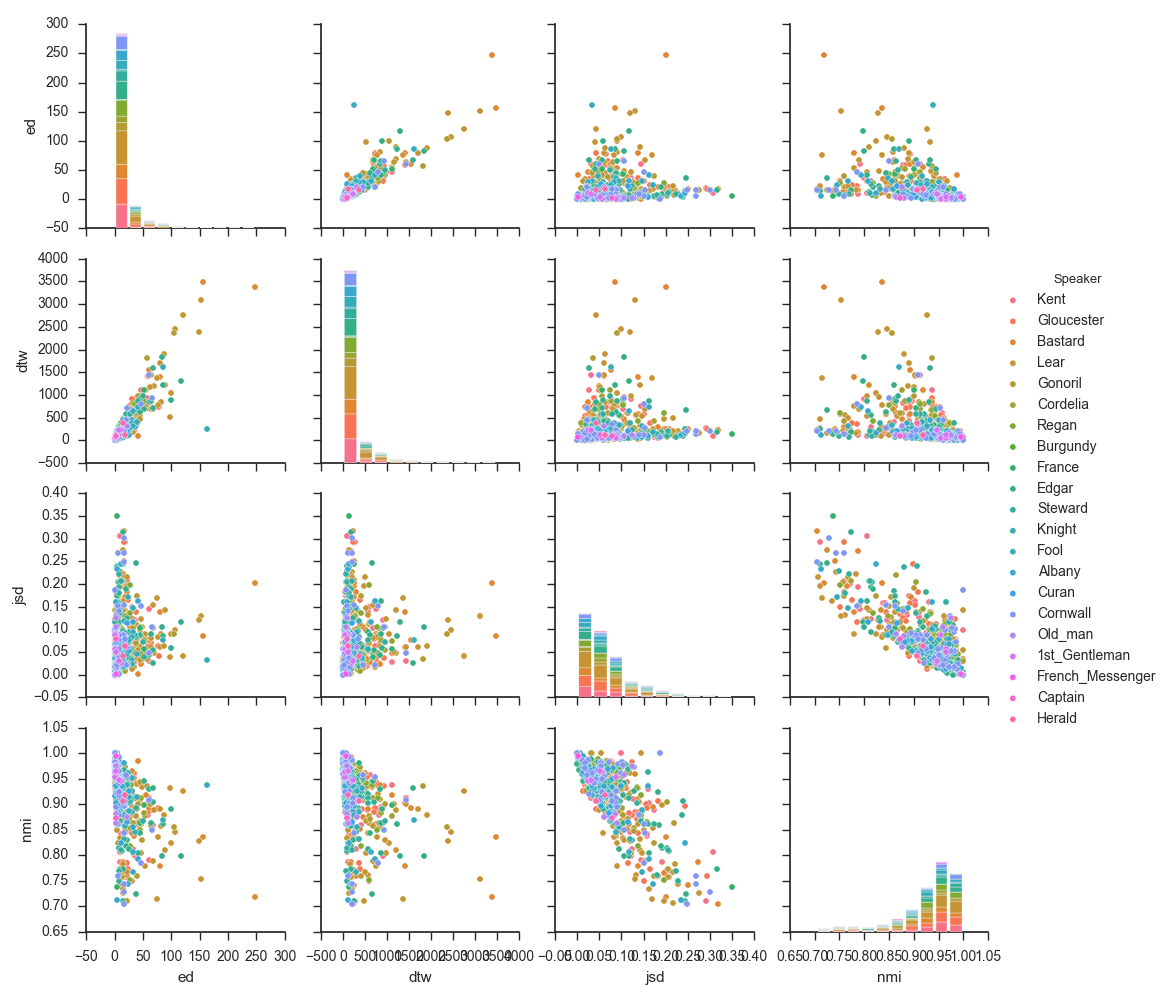
- The (diagonal histograms) distributions for all four metrics are different.
- I.e. the tell us different things.
- However, DTW and ED are fairly strongly correlated (to do -- compute R value).
- Similarly, JSD and NMI are fairly strongly negatively correlated (to do -- compute R value).
- DTW/ED vs NMI/JSD are not strongly correlated.
Experiment 1.i
i) Compare Q-common and F-common. Calculate the Jensen-Shannon Divergence, the DTW cost, and the Edit Distance between them. These are chunks of Q and F that we consider to be essentially the same writing but printed 15 year apart, so let's get a baseline for how alike they appear by these three metrics. We could, for comparison, run the same tests for other Shakespeare plays that we are confident are by him alone that are available to us in Q and F form and that we consider essentially the same writing but printed about 15 years apart.
- These info metrics are to be calculated between corresponding speeches in Q and F
- However we do not have a definitive lookup table of Q <-> F speeches.
- Try to develop a heuristic ...
1) Corresponding Speeches must be at least fairly close .... Say within any scene and for any speaker the speech, the speech numbers must be within 6 if each other. This prevents lots of possibilities but is still slack enough to cover the fuzzy matches. 2) For speeches to match the e.d. must be low-ish ... So we remove any speech pairs that are mismatches using e.d. by this criterion .... 3) Also for speeches to match their m.i. must be high-ish ... Again remove mismatches ....Code
Results
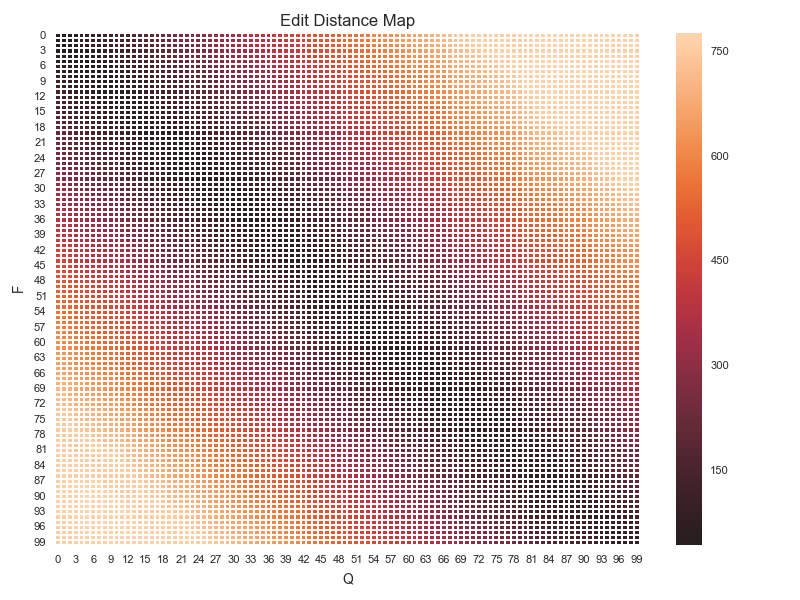
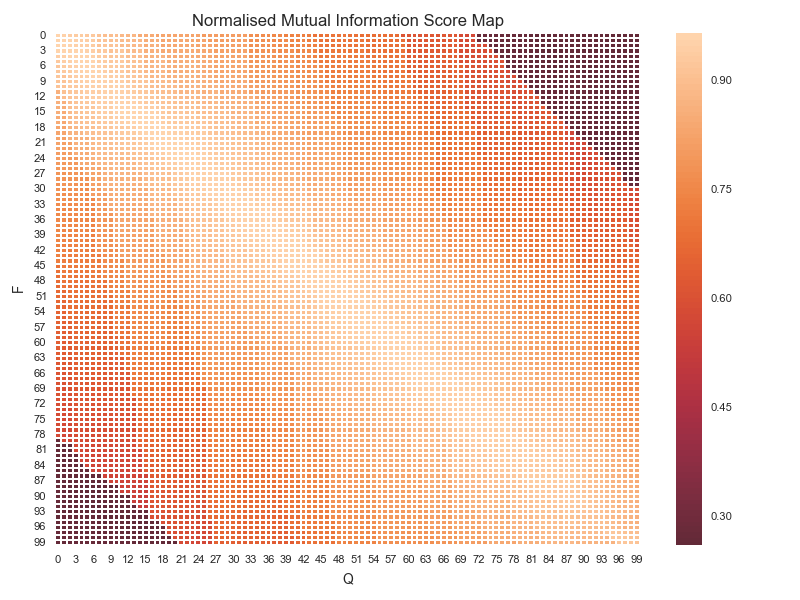
- Eg Edit distance
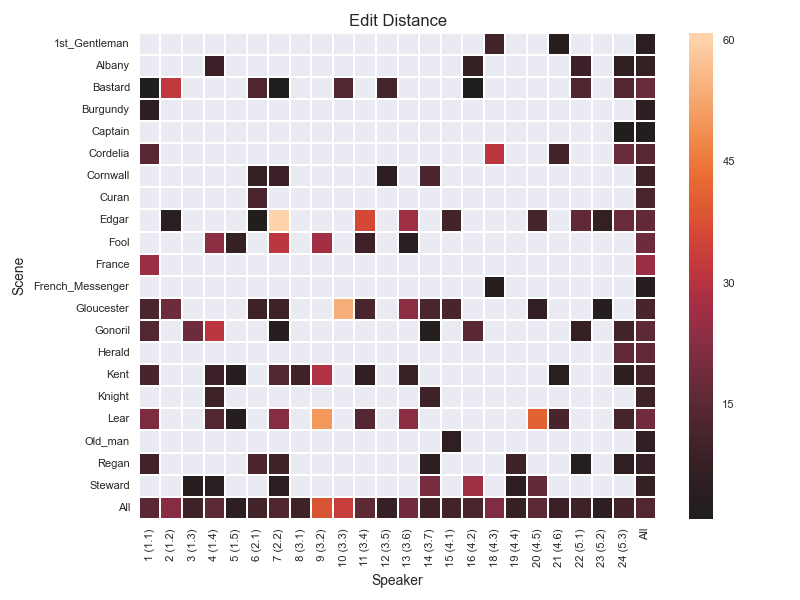
- The "baseline" for comparisons is the "Al"l row/column.
DECISION
- Try to find speeches in the Lr F/Q common xml that do not match by "speech number"
Experiment 1.ii and 1.iii
ii) Compare Q-only with Q-common. Count the frequencies of occurrence of the top 100 function words and then apply i) Principal Component Analysis and ii) Nearest Shrunken Centroid to the counts to see if the texts seem to be the same style in this regard. Our starting hypothesis is that the Q-only matter is material cut from the play after Q was published, so we expect Q-only and Q-common to test the same in style. (This somewhat replicates the tests in the second half of the Kinney-on-King-Lear chapter.)
iii) Compare F-only with F-common. Count the frequencies of occurrence of the top 100 function words and then apply i) Principal Component Analysis and ii) Nearest Shrunken Centroid to the counts to see if the texts seem to be the same style in this regard. Our starting hypothesis is that the F-only matter was freshly written by Shakespeare about 6 years after he originally wrote the play, so we would expect these F-only and F-common to test roughly the same in style, whereas a great difference in style would suggest that someone other than Shakespeare wrote F-only. (This somewhat replicates the tests in the second half of the Kinney-on-King-Lear chapter.)
- TKL uses PCA on S. and Fletcher, and plots centroids not NSC
- We could use NCS buy doing DLDA type plots
- Used 200 function word list from C&K Appendix
- Ignored PoS (so just "which" not "which as relative" etc. etc.)
- Since would need to parse POS/VARDed elements ...
- Use sklearn for PCA
- Use seaborn plot 3d to plot first 3 principal components
- Compute centroids using np.mean.p
Code
Results
- PCA Centroids of Q-Common and F-common are coincident.
- Centroid of Q_Only sets bound/precedent for how far two sub-texts of the same work (Q) may differ.
- The Centroid for F-only is as close to Q-common/F-common as is Q-only.
- I.e. F-only appear to be "as similar in 'style'" to F-common/Q-common as is Q-only -- under this analysis.
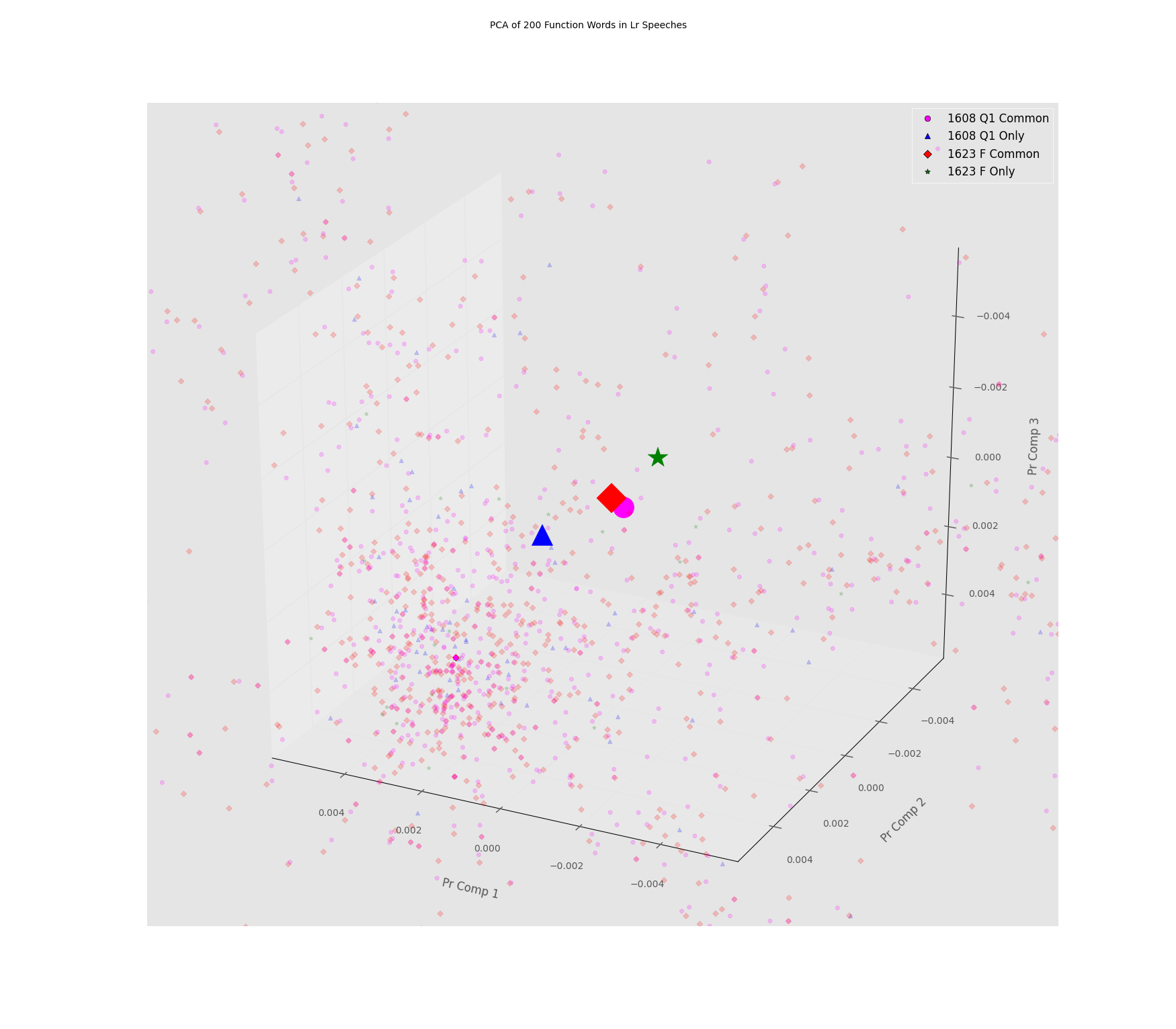
- For publication maybe focus on 2d plots of first two principal components...
Experiment 2
EXPERIMENT 2) "FIND-YOUR-PARTNER"
Take a play for which we have a quarto and a Folio text. Take the first 2000 words (dialogue, and stage directions, and speech prefixes) in the quarto and compare it to the first 2000 words in the Folio, using as a measure of the difference each of DTW, Jensen-Shannon Divergence, and Edit Distance. Record the value of the difference by each of these three metrics. Then move the 'window' in the Folio (but not the quarto) up by one word so that words 1-2000 of the quarto are being compared to words 2-2001 in the Folio. Take the same three measures of difference and record them. Then move the 'window' in the Folio up by word one so that words 1-2000 of quarto are being compared to words 3-2002 in the Folio. Repeat this until there are no more words left in the Folio. Review the three scores (one for DTW, one for Jensen-Shannon Divergence, one for Edit Distance) for the matches and find for each the lowest-matching segment in the Folio. Record this lowest matching segment as the best match for words 1-2000 in the quarto.
Then move the window in the quarto up by one word to words 2-2001 and reset the Folio window to words 1-2000 and again make the comparison, recording the difference for each of the three metrics. Then move the Folio window up by 1 so that quarto words 2-2001 are being compared with Folio words 2-2001 and again record the differences. Then move the Folio window up by 1 so that quarto words 2-2001 are being compared to Folio words 3-2002 and record the difference. Repeat until there are no more Folio words. Again review the scores to find the partner in F for Q's segment 2-2001. Repeat all of this for Q's segment 3-2002 and so on until there are not quarto words left. The result should be a mapping of each 2000-word segment in Q to the closest 2000-word segment in F, as detected by each of the three metrics, together with the score for that mapping (how alike the segments are). This should show where Q and F are much alike and where they are not.
Things that might be varied in this experiment:
Using segments smaller or larger than 2000 words
Using steps of more than 1 word each time
- The current database for Lr contains only speeches -- stage directions will require a separate table.
- So focus just on speakers and speeches
- These metrics compare pairwise strings of 2000 words from Q with strings of 2000 words from F.
- There are 26038 words in Q and 24527 words in F hence there are 638,634,026 (over 630 million) pairwise comparing to be preformed for each metric.
- Taking 2000 words (of varying length) produces strings of differing lengths, however jsd and nmi require strings of the same length.
- Hence we must do DTW first before we can calculate jsd or nmi.
- DTW is expensive.
- Hence this experiment will require A LOT OF COMPUTATION.
- Worse many of the comparisons are pretty pointless -- such as comparing the first 2000 words in Q with the last 2000 words in F etc. etc
- We therefore need to think some more about what this experiment is seeking to do.
Code
Results
- Using just the first 100 windows over Q and first 100 windows over F...
- Run time: 4mins -- so maybe need to run on Workstation not laptop.
DECISION
- Try to work with individual speeches rather than windows over 2000 words.
- See ...
Experiment 3
EXPERIMENT 3) "HE-SAID-WHAT?"
Take a play for which we have a quarto and a Folio text. Pull out all the speeches by one character who is common to both texts. (This might necessitate a manual mapping to show that character xxx in the quarto is the same person as character yyy in the Folio.) Putting all the speeches into one long chunk of text, measure the difference by each of Jensen-Shannon divergence, DTW, and Edit Distance between the chunk from Q and the chunk from F.
Things that might be varied in this experiment:
Rather than putting all of one character's speeches
into one long chunk of text, might subdivide by act and also by scene--requiring some manual mapping of Q act/scenes to Folio acts/scenes--so that we can see where in the play that character's speeches are most alike in Q and F and most different in Q and F.
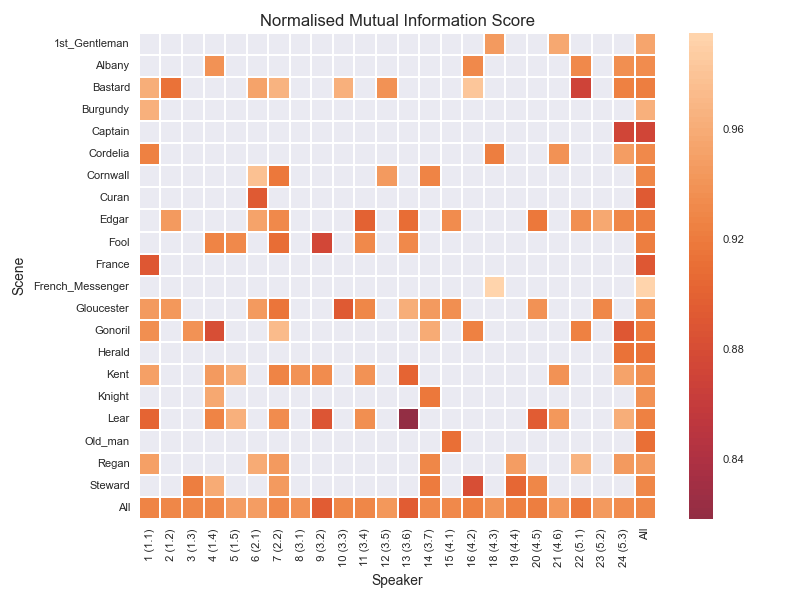
- I think this is covered by the speaker/Scene 2d analysis in the results for "Experiment 1" above:
Results
EEBO Texts
- Fletcher
- Validating against trilite.dtd w xmllint.... seems these use a different DTD version.
- DECISION: focus just on the S. xml texts we have in this particular DTD version.
S. Texts